
Annotation and Editing Collections¶
The annotation and editing page for workspace collections [1] implements a minimal version [2] of the open source Javascript “CKEditor” http://ckeditor.com/ which allows the texts to be edited and annotated. Editing works as you would expect, including cut/copy/paste options.
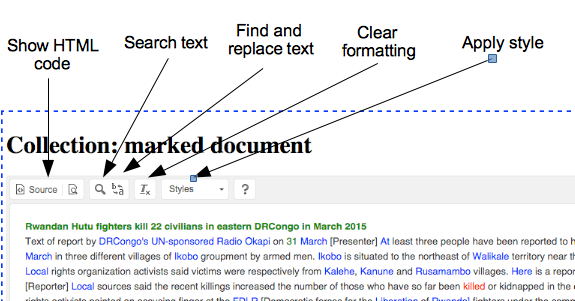
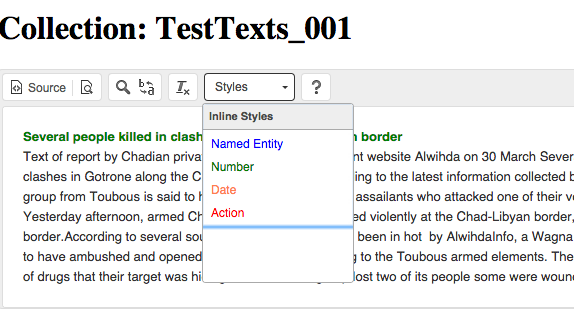
Annotation is handled with the Styles drop-down menu in the window
toolbar which should show both
the standard CIVET categories—named-entity, number and date— and any
user-specified categories. To annotate, just select the text you want to
annotate and then select the annotation to apply.
The following options are available on this screen
Annotate the collection:
This applies the automated markup system which currently annotates the following categories of words and phrases:
- Named-entities:
- This is based on capitalization; consecutive capitalized words are combined.
- Location [optional]
- When the
Use preposition-based geographical markuppreference is set toTrue, these are named-entities which are preceded somewhere in the text by prepositions in the list'at','to','in','from'See additional discussion in the “Preferences” chapter.- Numbers:
- Digits and numerical words and phrases such as “one” and “two-hundred.”
- User-specified categories:
- See the discussion of categories
Annotation is done automatically when
Always apply annotationpreference is set toTrue; this can be changed on the “Preferences” screen.
Save edits and select new collection:
This saves whatever annotation has been done to the internal database [3] and returns to the collection selection screen : this option would be used if you are only annotating text rather than coding them. Annotations are saved in thetextmkupfield of the YAML file along with the date of the annotating and the coder ID.
Save edits and code the collection:
This saves whatever annotation has been done to the internal database and goes to the coding and text extraction page
Discard edits and select new collection:
This discards the edits and returns to the collection selection screen.
Download workspace and return to home screen:
This downloads the current workspace without doing any coding.
Comments on annotation and editing¶
Associated codes in brackets following a term can be edited: when writing variable values, the system will simply be looking for a value in a bracket that occurs at the end of a string.
A word or phrase can be annotated only once. [4] The user-specified
categorywords are annotated before the general named-entity, so if a named entity occurs in acategory, that will take precedence. Similarly, any numbers that occur in acategoryphrase will be part of the phrase, not separately marked as numbers.Words and phrases in
categorylists are evaluated in the order they are listed, which can be used to establish precedence.Consider the sentence
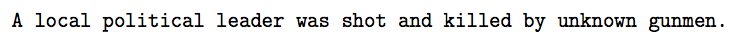
The category listing:
category:action [red]
shot and killed [4], killed [1], wounded [2], bombed [3]
would result in the annotation

whereas category listing:
category:action [red]
killed [1], shot and killed [4], wounded [2], bombed [3]]
would result in the annotation

because the “killed” part of the phrase “shot and killed” has already been annotated, and the remainder does not fit any of the patterns.
CIVET does not identify a capitalized word as a named-entity if it occurs as a single word and is in the list of common “stop words” in the file
djcivet_site/djciv_data/static/djciv_data/CIVET.stopwords.txtIn other words, “The” will be included as part of a named-entity in the phrase “The New York Times” but not in the phrase “The village was…”
Words referring to numbers such as “one”, “ten” and “fifty” have the corresponding numerical value added in brackets following the number; these phrase and their associated values are obtained from the file
djcivet_site/djciv_data/static/djciv_data/CIVET.numberwords.txt[5]This file only contains the most commonly-encountered phrases; bracketed values can be added manually as well.
- At present, CIVET does not recognize leading punctuation—typically quotes—and will not automatically mark named entities or numbers beginning with this: this is on the list of changes for the future. It does handle most trailing punctuation. In named entities, the lower-case prefixes “al-”, “bin-” and “ibn-” are recognized as part of a name. [6]
Footnotes
| [1] | If you are not seeing this screen, civet_settings.SKIP_EDITING is
probably set to True: this can be changed on the “Preferences”
screen. |
| [2] | that is, the version of ckeditor deliberately uses only a very
small set of the features that are available for the editor: if you
want to customize this, additional features can easily be added. |
| [3] | That is, the data is saved on the machine where CIVET is running; it is not saved on your local machine until the workspace is downloaded. |
| [4] | It would be possible to modify the system to allow for phrases to be in multiple categories, but at present this seems like a low priority; such a feature may or may not be included in future versions. |
| [5] | Looking for a little programming exercise?: This needs more
development in at least three ways. First, generate all of the
standard English equivalents, e.g. “eighty-five”, since these follow
a simple set of rules. Second, and perhaps more important, allow the
user to specify the values for common approximations such as
“several,”, “many” and “dozens.” The second can be done by just
editing the file CIVET.numberwords.txt, though generally we don’t
want the user to have to figure out how to do that. Finally, there
should probably be some error checking to make sure the value in
brackets is actually a number: CIVET will just copy the value in
brackets without trying to convert it, but non-numbers will
presumably create issues further down the processing pipeline. |
| [6] | This list can be extended in the regular expression pat1 in
civet_utilities.do_NE_markup(). |