
Coding and Text Extraction¶
The CIVET coding form screen in the demonstration version is shown below. [1]
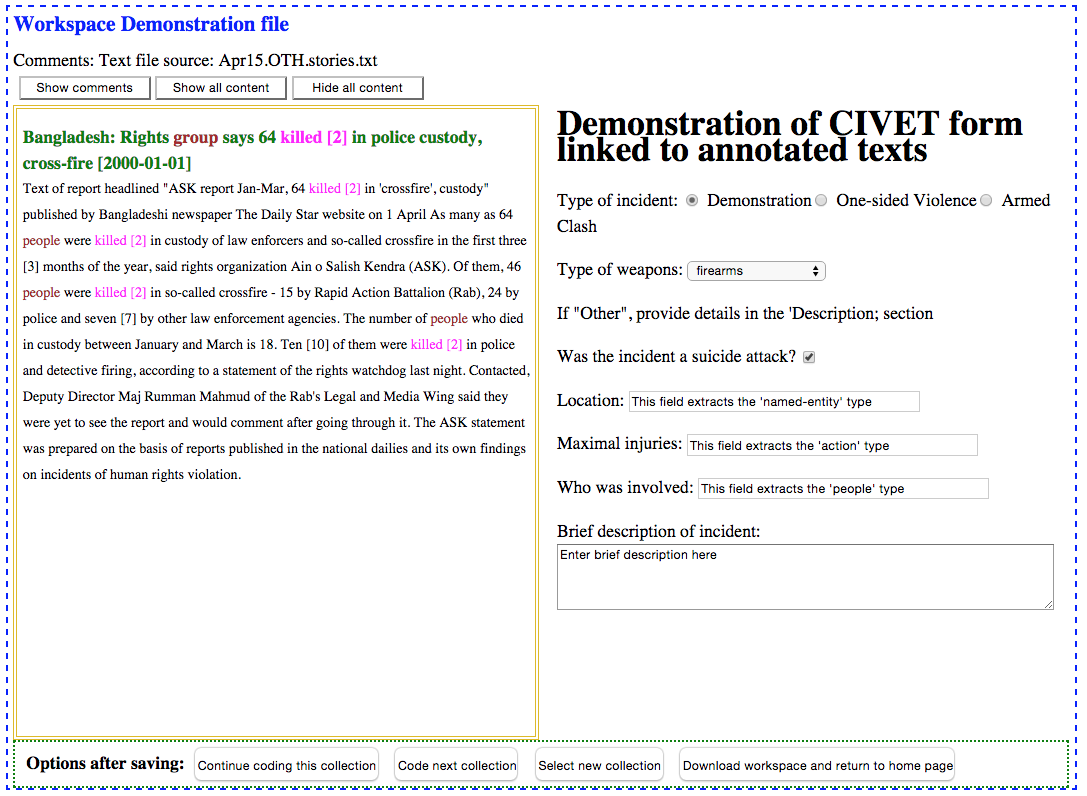
The general operation of the coder/extractor is described below:
Unless
civet_settings.SHOW_ALL_CONTENT = True, only the content of the first text will be expanded; to expand or collapse these, click on the lede (green text). [2] The date of the article follows the lede in brackets.Shift-click on the lede will delete the text: the lede and text disappear and from any subsequent codings. The text actually remains in the workspace file until it is permanently removed (or the deletion is reversed) in the workspace management. See the notes below for more details on this operation.
There are three controls at the top of the text display:
Show/hide comments: toggles the display of the comments andsources for each text: these are initially hidden. [3]
Show all content: shows the content for all of the ledesHide all content: hides the content for all of the ledes
Clicking a text entry boxes associated with an annotation category will highlight the relevant words in text: In the demonstration version these are
- Location:
named-entities
- Maximal injuries:
actions
- Who was involved:
people
The ‘tab’ key cycles between the coding fields, or an option can be selected using the mouse.
When an annotated category field is active, all of the words and phrases in the text for that category are changed to red, with the first word that is in an expanded text highlighted using a green background. The arrow keys can be used to move the highlighted text into the field. These operate as follows:
- Right arrow:
Highlight the next text in the category
- Left arrow:
Highlight the previous text in the category
- Down arrow:
Replace the contents of the field with the highlighted text.
- Up arrow:
Append the contents of the field with the highlighted text. The appended texts are comma-delimited.
If the highlighted text is off the screen, the window will automatically scroll to place the text on the bottom of the screen. If the text contains no words in the category, a pop-up window will alert you to this.
If an annotated category field has an associated source field, that information will be automatically replaced or added when the down or up arrow is used. If a reference is already in the source field and information is being added from the same source, this will not be repeated. References can also be added to source fields using copy-and-paste.
Note: If there are a number of phrases in the target category—this occurs frequently for the named-entity and geographical-entity categories—and the phrase you want to extract is not in the first expanded block, click on the ledes to collapse them until you get to a text that does contain the target phrase. If the earlier ledes collapsed, the first phrase highlighted will be in the expanded lede, so you will not need to hit the right-arrow key many times to highlight and extract it.
Copy-and-paste from the text to the data fields work as you would expect; text can also be entered and edited manually.
If bracketed values are included in the string, the system takes the value from within a set of brackets that is the final item [4] in the phrase: earlier sets are assumed to be part of the text. For example, the value of the phrase
Islamic State [ISIS][mnsa]will be “mnsa”; the value of the phraseIslamic State [ISIS] militiawill be “Islamic State [ISIS] militia”.To save a set of coded fields, click one of the buttons along the bottom. At present, all three buttons save; later versions add “cancel“ and “reset” options. The options are:
- Continue coding this collection:
Save the data internally, then return to the same text to code additional cases.
- Code next collection:
Save the data internally, then select the next collection in the workspace and go to the annotation screen.
- Select new collection:
Save the data internally, then select a new collection
- Download workspace and return to home screen:
This downloads the workspace with the coded cases to the local machine. The Manage workspace facility can then be used to download any coded cases.
Note on deleting texts¶
Deleting a text changes the value of the textdelete field to
True: the text remains in the workspace file but will not be
displayed again. Deletion also generates a case with the standard
casedate and casecoder fields and the following fields in the
casevalues dictionary
_delete_ : True
_textid_ : textid for the deleted text
This can be used to track the deletion of specific texts. version Beta-0.9 does not have any internal utilities for using this information but those functions may be added in a later version.
Deletion is tracked through the hidden text field deletelist
in civet_coder.html.
Footnotes
| [1] | The form displayed is specified in the file
and can be modified if you want to experiment. |
| [2] | If you are switching back to the text from a text-extraction box, you will need to double-click: the first click switches the focus to the text; the second toggles the content |
| [3] | If the textcmt field for the text block was empty, the display will show
Comment: ----. If the textbiblio field for the text block was empty,
no Source: line will be shown. |
| [4] | Specifically, the system checks whether the final character in the
string that is not whitespace is ‘]’. The output when the system is
expecting to find a bracketed value and does not is controlled by
the preference civet_settings.USE_TEXT_FOR_MISSING which can be
changed on the “Preferences” screen. |